
一、InfluxDB使用场景
InfluxDB是一种时序数据库,时序数据库常用于监控场景,比如运维和IOT(物联网)领域,此类数据库旨在存储时序数据和实时计算。
如:将服务器上的CPU的使用情况每隔5秒向InfluxDB中写入一条数据,在图形界面中写一个查询过去每10分钟CPU的平均使用情况,再将该查询开发一个定时任务,每10秒钟执行一次并配置一条规则:查询执行结果 > xxx,就立即触发告警。
上述就是一个监控指标的场景,在IOT领域中也有大量的指标需要监控,比如:机械设备的传感器频率、农田湿度温度等等。
时序数据库相对关系型数据库而言,时序数据库专注的是写入性能,时序数据库不关心事务、不关注更新操作(只写不改)。通常指标数据都是关心最近某段时间的数据,之后的数据基本不会再用。时序数据库的设计特点是冷热差别明显,对最近的数据时序数据库会优先加载到内存中。
二、InfluxDB版本比较和选型
时序数据库一般用于在监控场景,大体上,数据的应用可以分四部分:
- 数据采集
- 存储
- 查询、聚合
- 告警
对应InfluxDB 1.x开始也推出了TICK生态全套的解决方案:
- T:Telegraf 数据采集组件
- I:InfluxDB 数据存储组件
- C:Chronograf 用户UI数据管理功能
- K:Kapacitor 后台处理报警信息
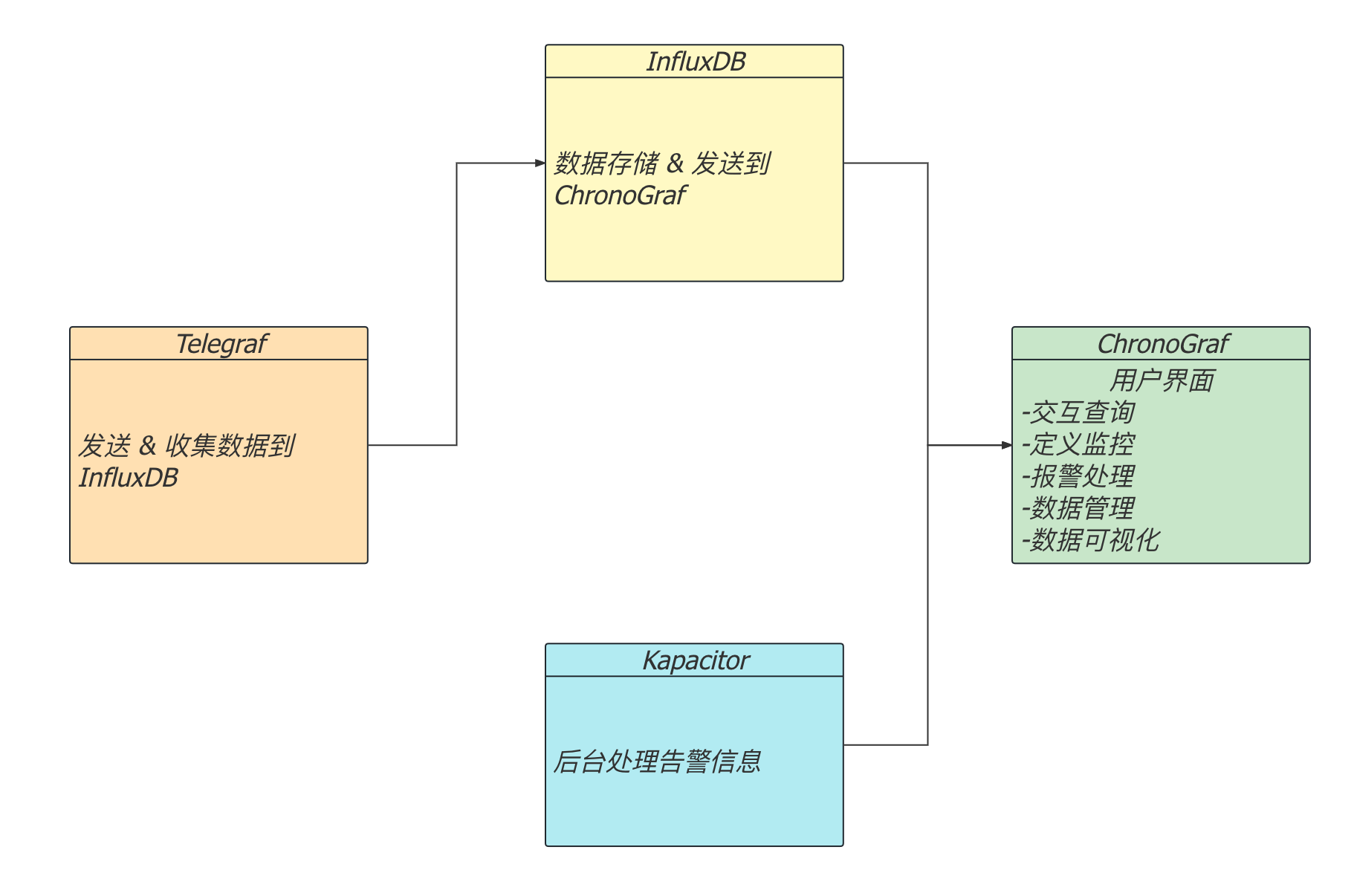
在InfluxDB 2.x后已经把C、K合并到了I中了,这是两个版本在生态上的差别,在2.x上易用性也随之提高了一个等级:我们只需要安装InfluxDB就得到一个管理UI界面并且附带了定时任务和告警功能。
T是一个单独的插件,专注于收集各种外部中间件的数据写入到InfluxDB中,这个需要单独研究该插件的使用。
安装下载地址:https://portal.influxdata.com/downloads/
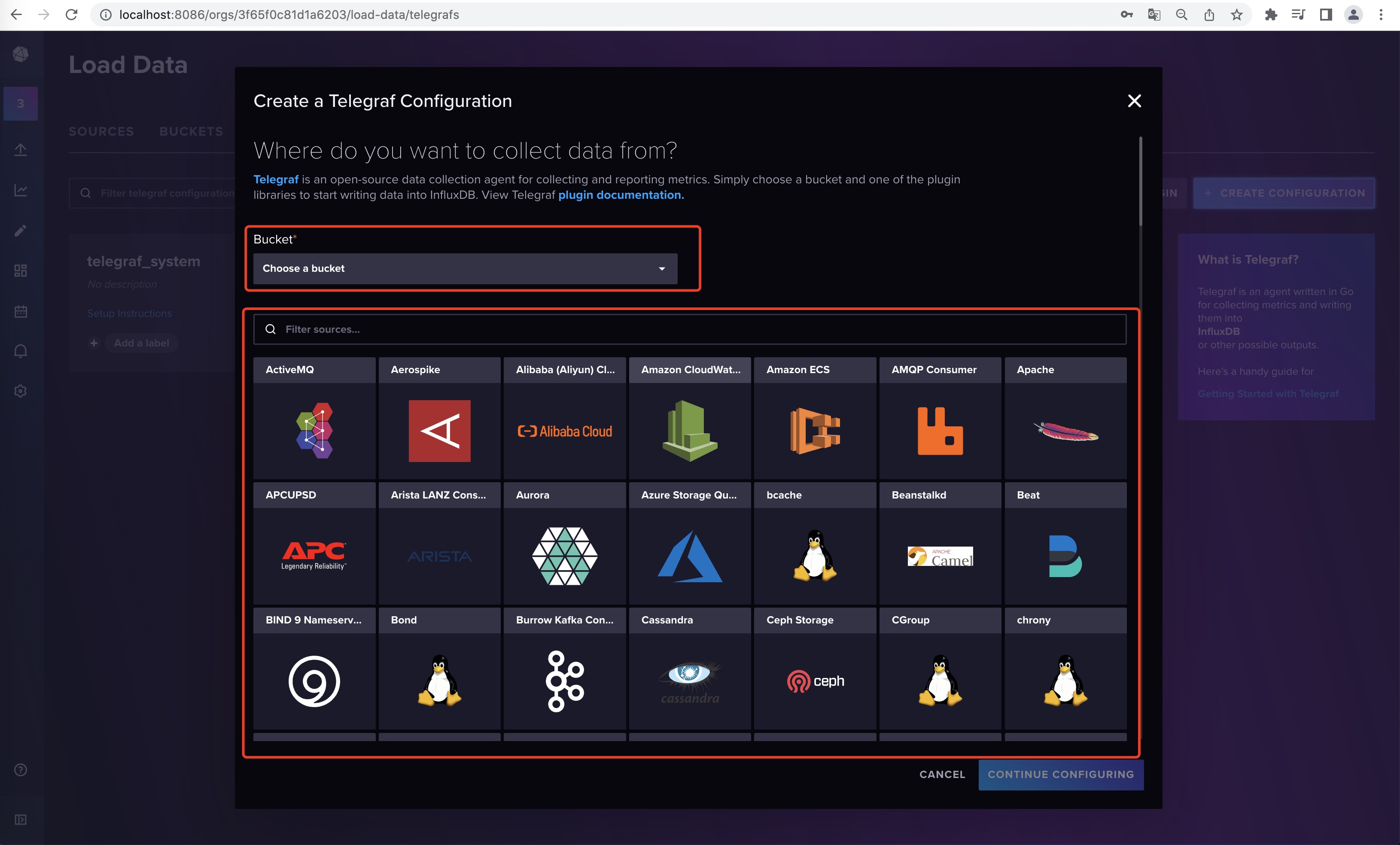
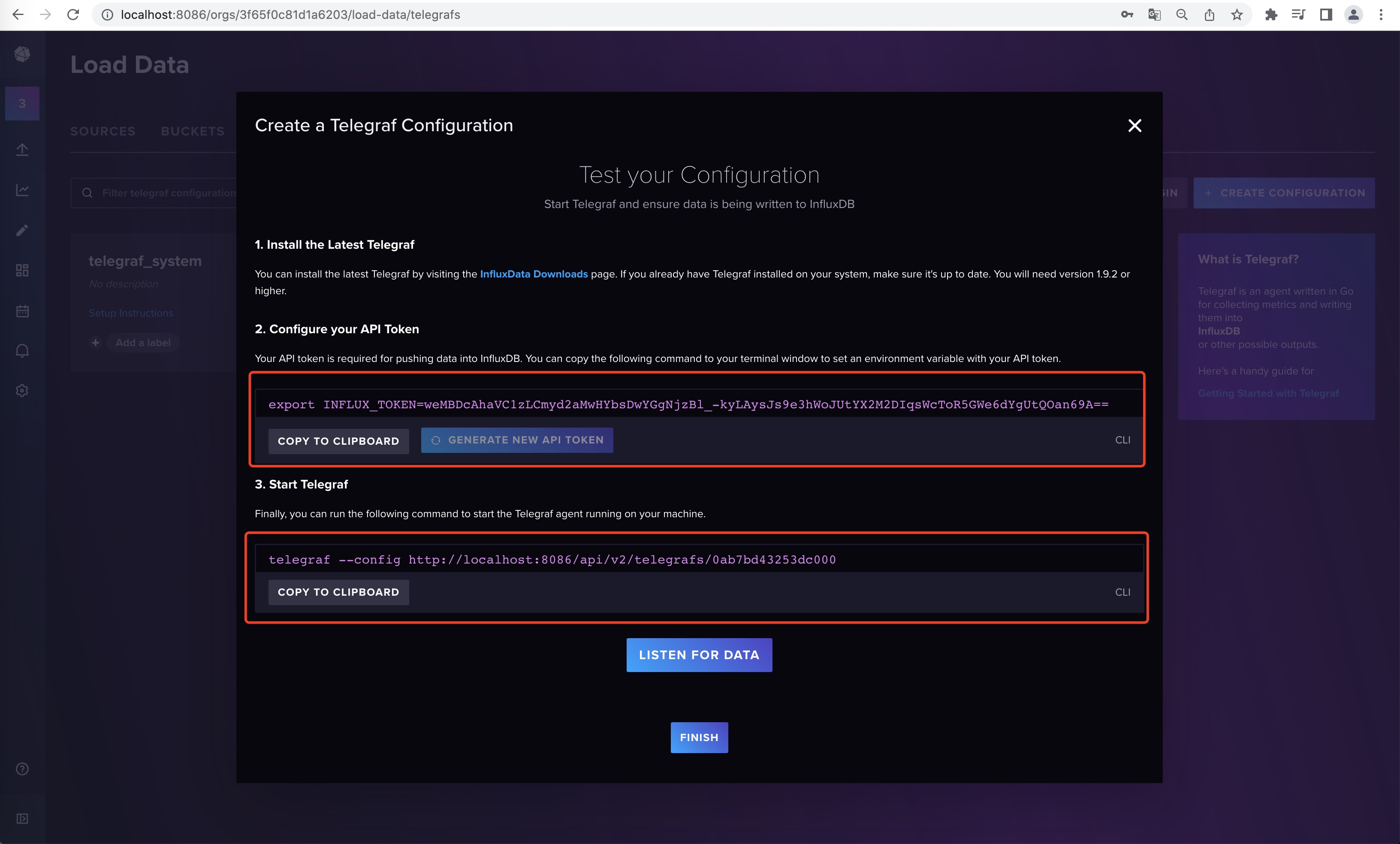
下面是在web界面中新增Telegraf的配置文件,它已经给支持了非常多的中间件产品,就按照它的示例去给Telegraf机器上设置环境变量和启动即可使用。
2020年InfluxDB推出了2.0版本正式版,底层引擎相差不大,都是基于TSM Tree。但多了一些概念的转变如:db换成了org,新增了bucket。另外查询语言方面优先使用Flux查询语言,使用函数与管道符。Flux语言从1.7版本已经开始提供,但一直在优化和修改,在1.8结束的版本还是优先使用InfluxQL语言操作,在2.0版本开始全面推进Flux语言,一直在优化和改进,目前2.6版本也趋向完整并提供更多的支持中。
目前的InfluxDB只有单节点版本开源,集群版本是需要商业化的购买。并且1.x版本存在安全漏洞,2.x版本已经全面升级了授权功能,所以选2.x版本是当前不二选择。
三、InfluxDB安装
请到官网下载对应的操作系统版本进行安装即可:https://docs.influxdata.com/influxdb/v2.6/get-started/setup/
安装后启动就会暴露8086端口一个web界面,填写用户名登录信息,必须初始化一个组织(Org)和存储桶(Bucket)。Continue后选择quick start即可。
- Organization:可以理解为数据库(DB)
- Bucket:可以理解为Schema
- Retention Policy:时间保存策略即:该Bucket内的数据保存多少天,过期数据自动清理。
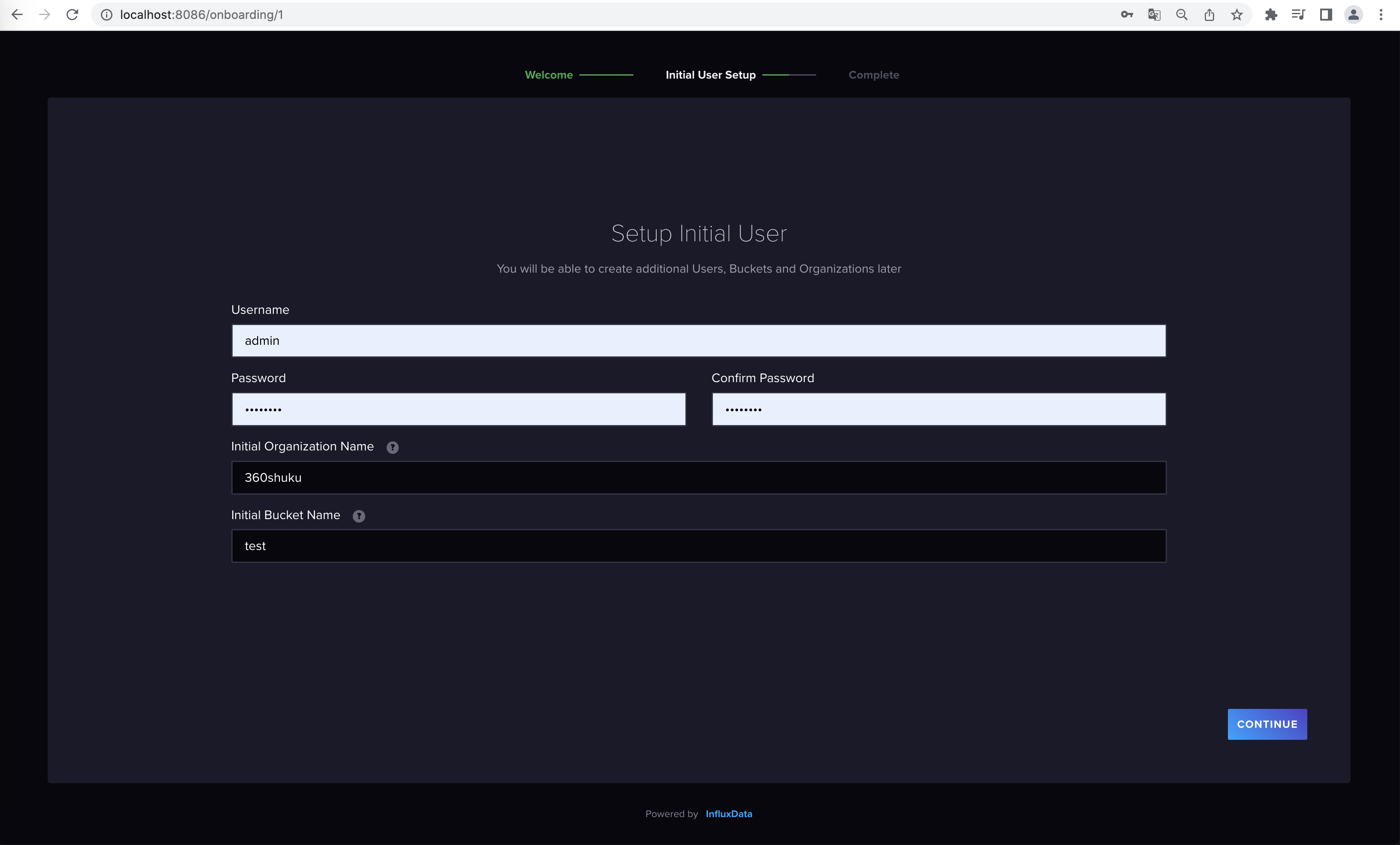
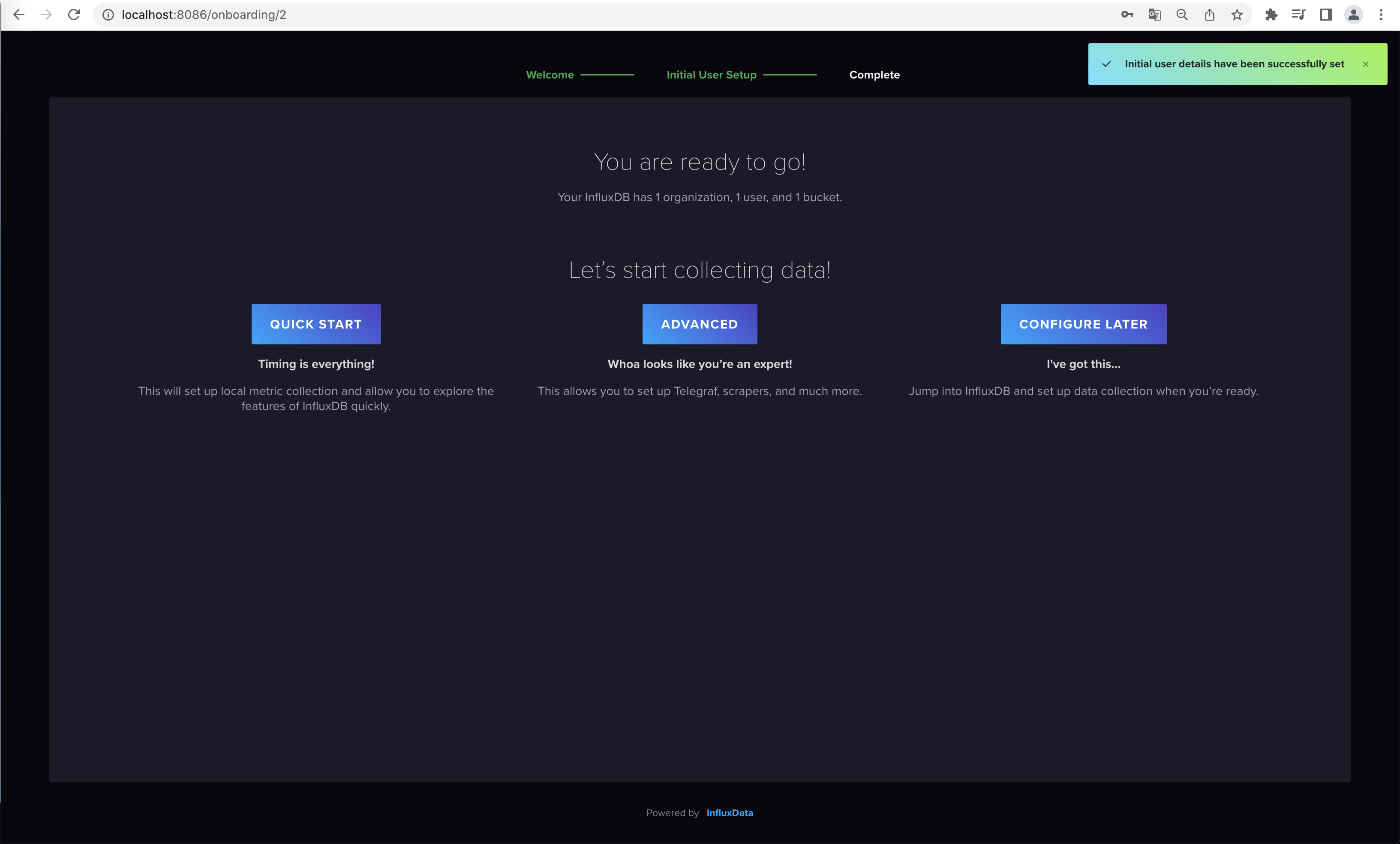
第一次只有初始化Bucket默认是该桶数据无过期时间,可以在Bucket界面修改过期时间配置(RP),接下来新增Bucket就出现RP选择框了
四、如何与InfluxDB交互
InfluxDB启动后会想外界提供一套HTTP API,外部程序通过HTTP API即可与InfluxDB进行通信,从2.x开始各种客户端与InfluxDB交互都离不开Api Token。
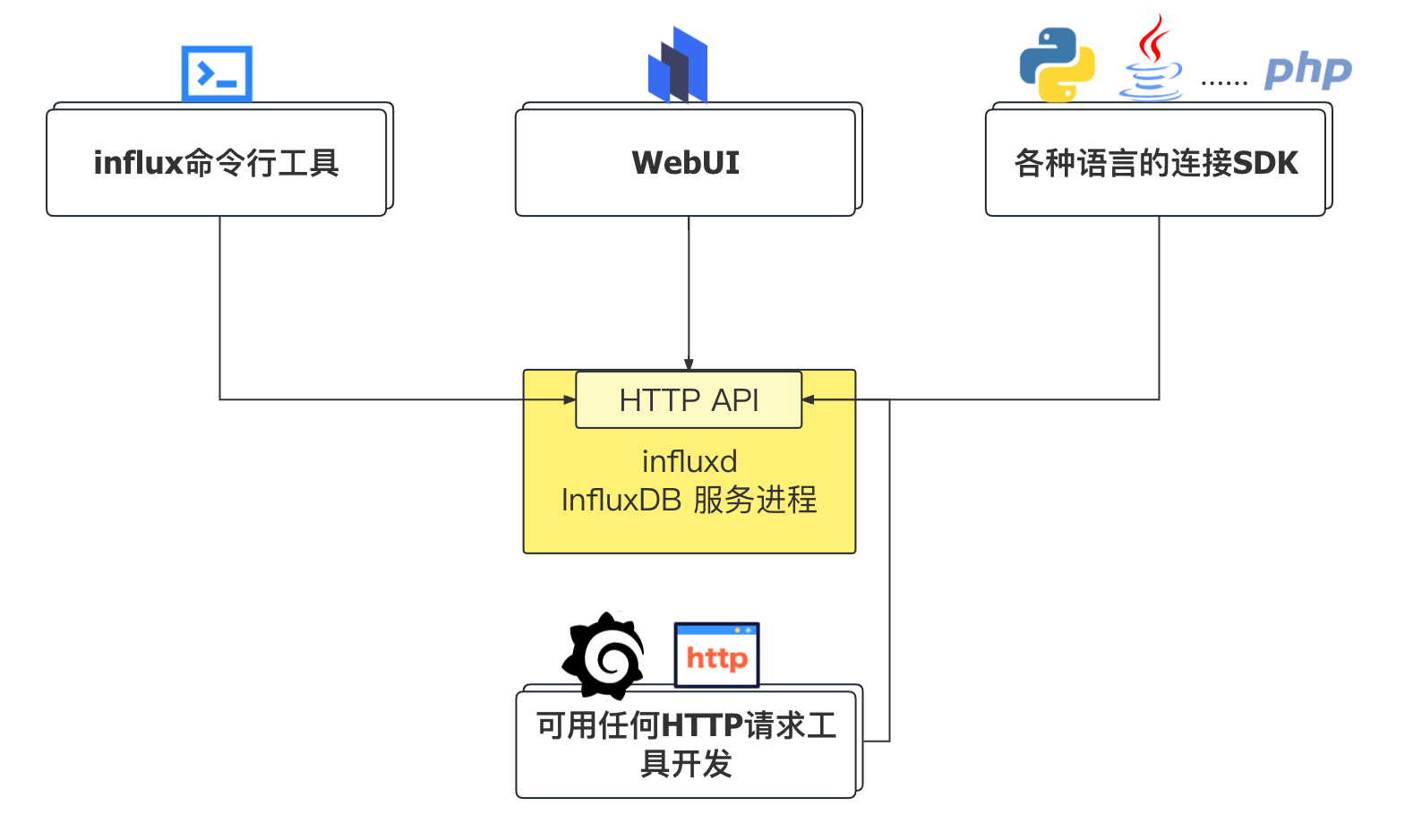
下图是UI中新增Api Token界面
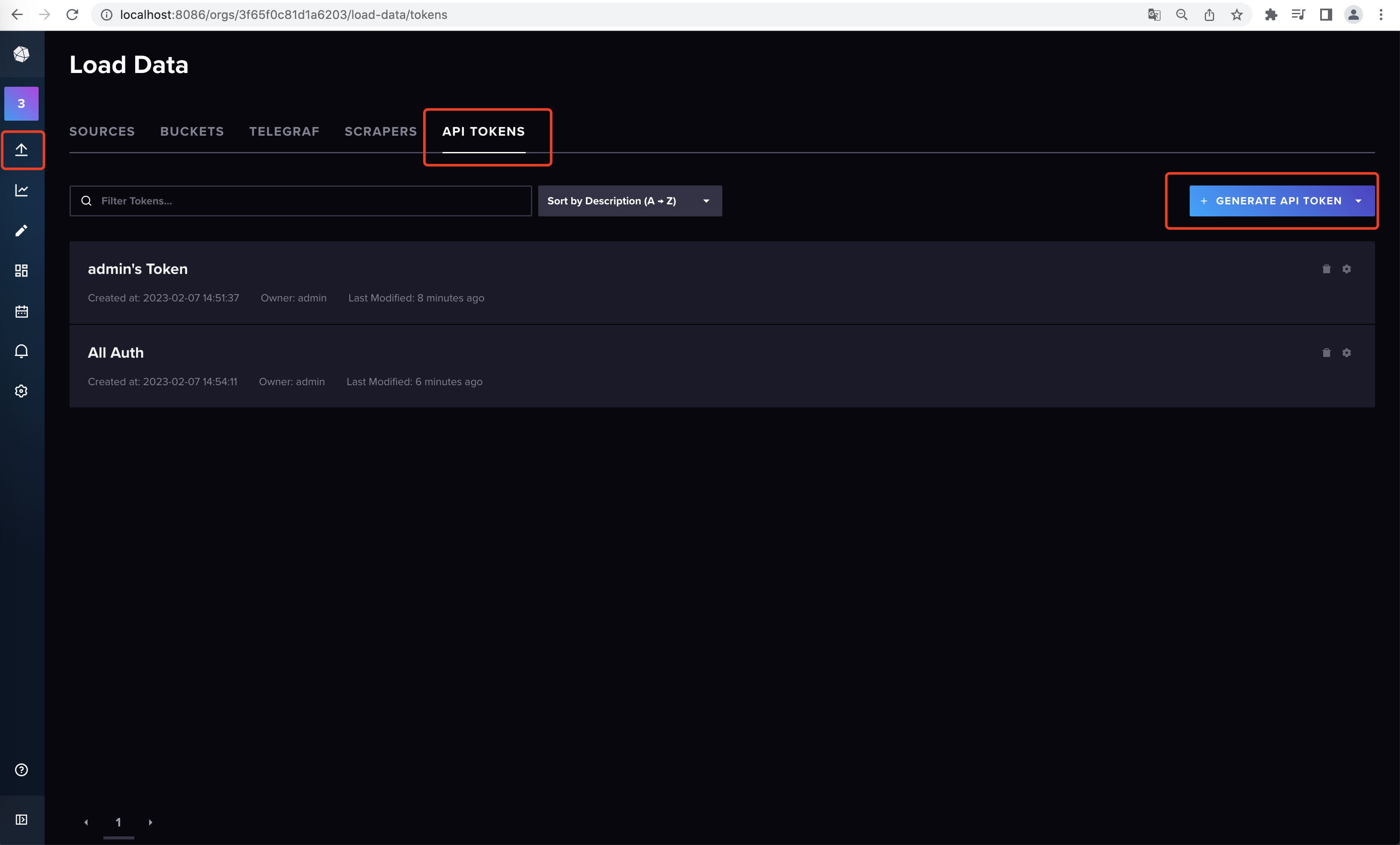
Sources里面提供了快速使用各个语言的SDK示例可以参考,File Upload中有几种写入数据的快速方式可以通过UI界面去操作写入。
五、InfluxDB数据行协议
InfluxDB行协议是它独创的一种数据格式,由文本构成,只要符合这种数据格式就能讲数据写入库中。每条数据使用换行符分隔,一行数据有下面4种元素构成。
measurement(度量名称,也可以理解为一张表)
tag sets(标签集,类似mysql的索引)
field sets(字段集)
timestamp(时间戳,必须字段,类似mysql的id字段)
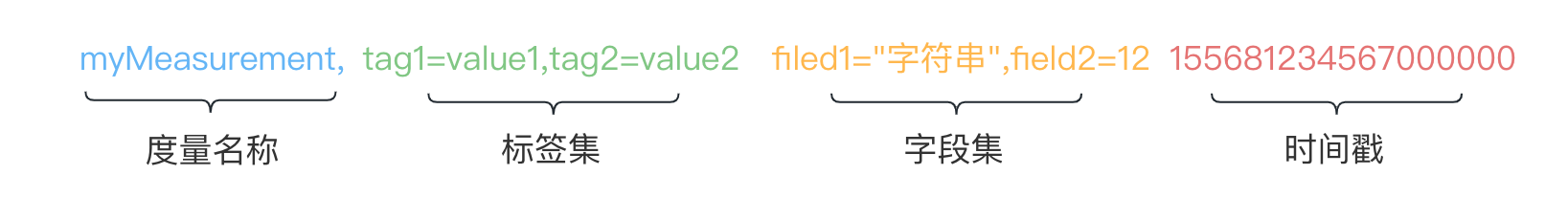
myMeasurement1,tag1="aaa",tag2="bbb" field1="ccc",field2="ddd" 1675822812745000000
myMeasurement1,tag1="aaa",tag2="bbb" field1="ccc",field2="ddd" ##时间戳可以省略,默认是插入的当前系统时间
myMeasurement2 field1="ccc",field2="ddd" 1675822812745000000 ##如果表名没有逗号分隔默认是没有tag
为什么measurement和tag之间不用空格呢? 请看下图解释

InfluxDB是个双索引结构,前面的是维度索引,后面的是一个有序的时间索引。
六、时序数据库的数据模型
想要正确使用时序数据库,就必须理解时序数据库的数据管理逻辑。以下我们拿关系型数据库跟时序数据库做个比较。
如下是我们常见的关系型数据库中的数据,其中id、type、time建立了索引列,number非索引列。
| id | type | time | number |
| ---- | ---- | ------------------ | ------ |
| 1 | aaa | 146700702100000000 | 2 |
| 2 | aaa | 146700702100000000 | 4 |
| 3 | aaa | 146700702100000000 | 12 |
| 4 | aaa | 146700702100000000 | 3 |
| 5 | bbb | 146700702100000000 | 4 |
| 6 | bbb | 146700702100000000 | 3 |
| 7 | bbb | 146700702100000000 | 5 |
| 8 | ccc | 146700702100000000 | 7 |
| 9 | ccc | 146700702100000000 | 6 |
如下是InfluxDB时序数据库的表示方式。时序数据库有一个序列的概念SERIES,从下面的数据体现来看,Tags是一个Key,Values是一序列的时间内List列表,如果要查询type="aaa"可快速的将这一批数据全部命中,我们如果再指定时间戳的范围,那么查询这些数据会更加的快速。
我们看到关系型数据库一般是以行的数据格式存储。在关系型数据库中查询会是先查询出ID,再把ID内的数据查询出来,这是在查询上的略微差别;另外一点是InfluxDB会将索引上的数据进行范围压缩,让这些数据占用空间尽可能的小。我们看到关系型数据库type的值很多重复的,每一行都出现,而在InfluxDB中就出现一次,再列举出time、number字段,所以InfluxDB体检会更小。
所以InfluxDB中查询出来的这些Values就是序列(Series),它的一行数据叫点(Point),每新增一行就叫Point。我们前面讲到InfluxDB是双索引结构:Tags是索引、Time是索引,那么我们在查询的时候用Tag定位整个序列,再用Time范围过滤我们的Point。
Name: my_test
Tags: type="aaa"
┏━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━┓
┃ index ┃ time ┃ number ┃
┣━━━━╋━━━━━━━━━━━━━━━━╋━━━━━━━━┫
┃ 1┃ 1675844398225168896.0000000000┃ 3.0000000000┃
┃ 2┃ 1675845424852518912.0000000000┃ 2.0000000000┃
┃ 3┃ 1675845484391100928.0000000000┃ 4.0000000000┃
┃ 4┃ 1675845553342360064.0000000000┃ 12.0000000000┃
┣━━━━┻━━━━━━━━━━━━━━━━┻━━━━━━━━┫
┃ 3 Columns, 4 Rows, Page 1/1┃
┃ Table 1/3, Statement 1/1┃
┗━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛
Name: my_test
Tags: type="bbb"
┏━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━┓
┃ index ┃ time ┃ number ┃
┣━━━━╋━━━━━━━━━━━━━━━━╋━━━━━━━┫
┃ 1┃ 1675844431280630016.0000000000┃ 5.0000000000┃
┃ 2┃ 1675845484391100928.0000000000┃ 3.0000000000┃
┃ 3┃ 1675845553342360064.0000000000┃ 4.0000000000┃
┣━━━━┻━━━━━━━━━━━━━━━━┻━━━━━━━┫
┃ 3 Columns, 3 Rows, Page 1/1┃
┃ Table 2/3, Statement 1/1┃
┗━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛
Name: my_test
Tags: type="ccc"
┏━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━┓
┃ index ┃ time ┃ number ┃
┣━━━━╋━━━━━━━━━━━━━━━━╋━━━━━━━┫
┃ 1┃ 1675844431280630016.0000000000┃ 6.0000000000┃
┃ 2┃ 1675845484391100928.0000000000┃ 7.0000000000┃
┣━━━━┻━━━━━━━━━━━━━━━━┻━━━━━━━┫
┃ 3 Columns, 2 Rows, Page 1/1┃
┃ Table 3/3, Statement 1/1┃
┗━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛
通过下面的图,我们可以看到measurement、tag_set、field组合成一个序列(series)。每个序列在内存和磁盘上紧密存放,所以当你查询这一序列的数据时,InfluxDB能快速的定位到这一序列的众多数据。你可以将measurement、tag_set、field视为索引,当然了它本身就是。

七、时间线膨胀
时间线膨胀是所有时序数据库都绕不开的问题,就是我们的时序数据库中的序列太多了,当序列过多的时候写入和读取性通常是断崖式的下降。
避免这类的问题是要注意:每一个tag的值是有限的枚举值,InfluxDB中默认是10万个最大,可调整但不建议调整,反之在生产中要限制在一千个之内。tag索引和关系型数据库不一样,关系型数据库是以唯一性最优。
InfluxDB查询优化步骤:
- 优先使用时间范围
- 再指定tag值
八、总结
InfluxDB2.x版本更新非常快,目前已经在2.6版本,如何启动和启动参数的变化需要使用者去查看文档,特此强调的是2.x版本没有使用磁盘存储和内存存储参数了,统一是磁盘存储,这也说明了1.x版本在实际使用的调优过程中在2.x版本都已经做了最优的默认。但是2.x的性能其实也没有太多的优化,在大量的数据查询还是非常的慢,超过几千万做个limit都难出结果,大部分查询都是优先用时间作为条件查最近的一小时内的数据居多,也印证了时序数据库的数据存储结构上和关系型数据库的差别。
使用场景不同,数据量不同,在存储数据落盘规范上也要给出响应的指导,如果使用者以关系型数据库的思维去写入数据,那么后期维护就会让人奔溃。
新的查询Flux语言也需要一些学习成本,期待下期再做个文章分享Flux语言的使用。