
前言
我们在工作中基本都会用到池连接技术,数据库连接池、HTTP连接池、线程池。深入了解其设计思路背后是为了解决频繁开启连接和关闭了解带来的性能开销,合理的复用连接池技术有效的减少创建和消耗带来的内存开销。
今天分享一下线程池的一些原理和示例,让我们更好的理解线程池的工作流程。
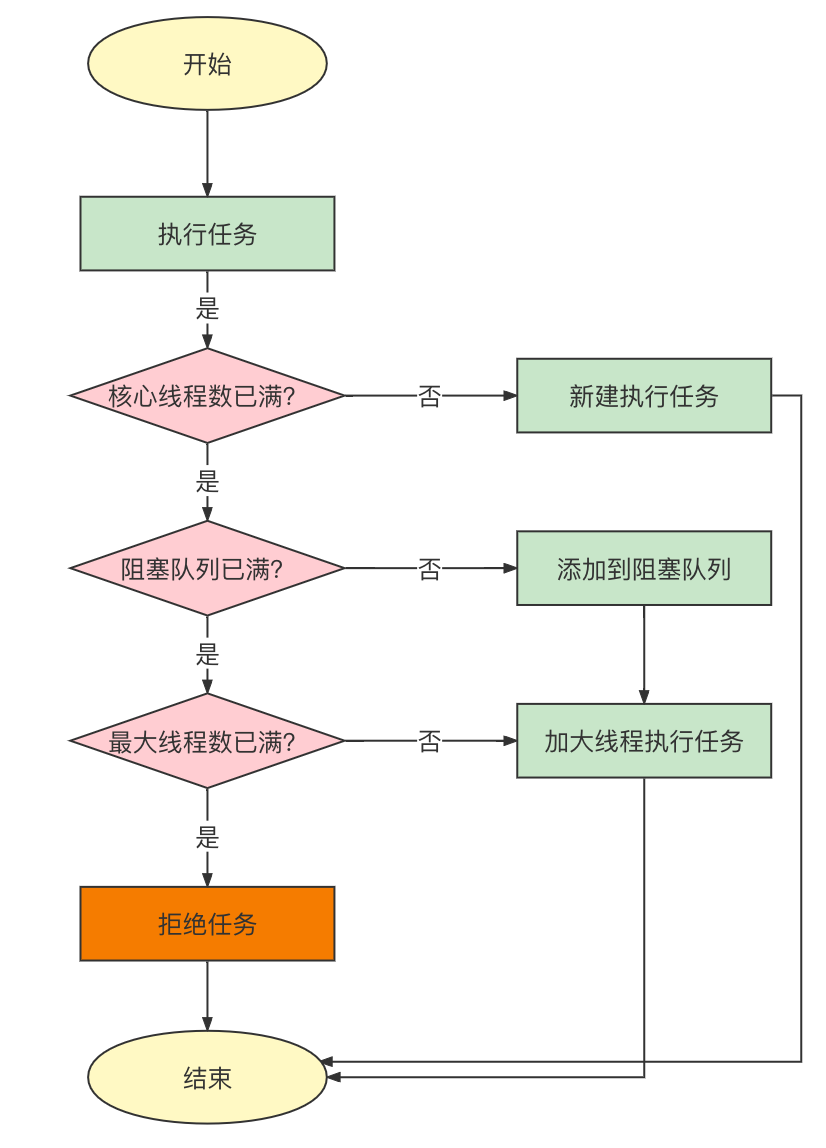
一般说线程池的几个核心参数的作用,什么情况下会使用到最大线程数?线程是通过哪个类创建出来的?拒绝策略有哪些?基本上大家都有了解,如当线程数>=核心线程数且任务队列满时就会新建线程数到最大线程数据的范围;如线程是由实现ThreadFactory接口的DefaultThreadFactory去创建线程的,源码中就是new Thread();当任务队列满时新的任务如何处理就看拒绝策略,默认的AbortPolicy就是抛异常。
| 拒绝策略类型 | 说明 | |
|---|---|---|
| 1 | ThreadPoolExecutor.AbortPolicy | 默认拒绝策略,拒绝任务并抛出任务 |
| 2 | ThreadPoolExecutor.CallerRunsPolicy | 使用调用线程直接运行任务 |
| 3 | ThreadPoolExecutor.DiscardPolicy | 直接拒绝任务,不抛出错误 |
| 4 | ThreadPoolExecutor.DiscardOldestPolicy | 触发拒绝策略,只要还有任务新增,一直会丢弃阻塞队列的最老的任务,并将新的任务加入 |
但是有了上面的了解,你是否知道线程池中的线程创建了多少个线程去执行任务的吗?我相信都不知道吧,我们通过一个实际例子来看一下线程池在一批队列中他的执行时间的变化,得出的一些线程数让我们更直观的感受一下这种参数设置的原理。
示例
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @author cookie.joo
* @date 2022-01-26
*/
public class ThreadPoolExecutorTest {
public static void main(String[] args) {
execute(5);
execute(10);
execute(11);
execute(20);
execute(30);
execute(40);
execute(41);
execute(45);
execute(50);
execute(51);
}
/**
* @param taskCount 任务数
*/
public static void execute(int taskCount) {
ThreadPoolExecutor executor = new ThreadPoolExecutor(
10,//核心线程数
20,//最大线程数
5,//非核心回收超时时间
TimeUnit.SECONDS,//超时时间单位
new ArrayBlockingQueue<>(30)//任务队列
);
System.out.println("总任务数:" + taskCount);
long start = System.currentTimeMillis();
//模拟任务提交
for (int i = 0; i < taskCount; i++) {
Thread thread = new Thread(() -> {
try {
Thread.sleep(500);//模拟执行耗时
} catch (InterruptedException e) {
e.printStackTrace();
}
});
try {
//默认拒绝策略抛异常
executor.execute(thread);
} catch (Exception e) {
System.out.println("任务" + taskCount + "被抛弃");
taskCount -= 1;
}
}
long end = 0;
while (executor.getCompletedTaskCount() < taskCount) {
end = System.currentTimeMillis();
}
System.out.println("任务总耗时:" + (end - start));
executor.shutdown();
}
}
解析
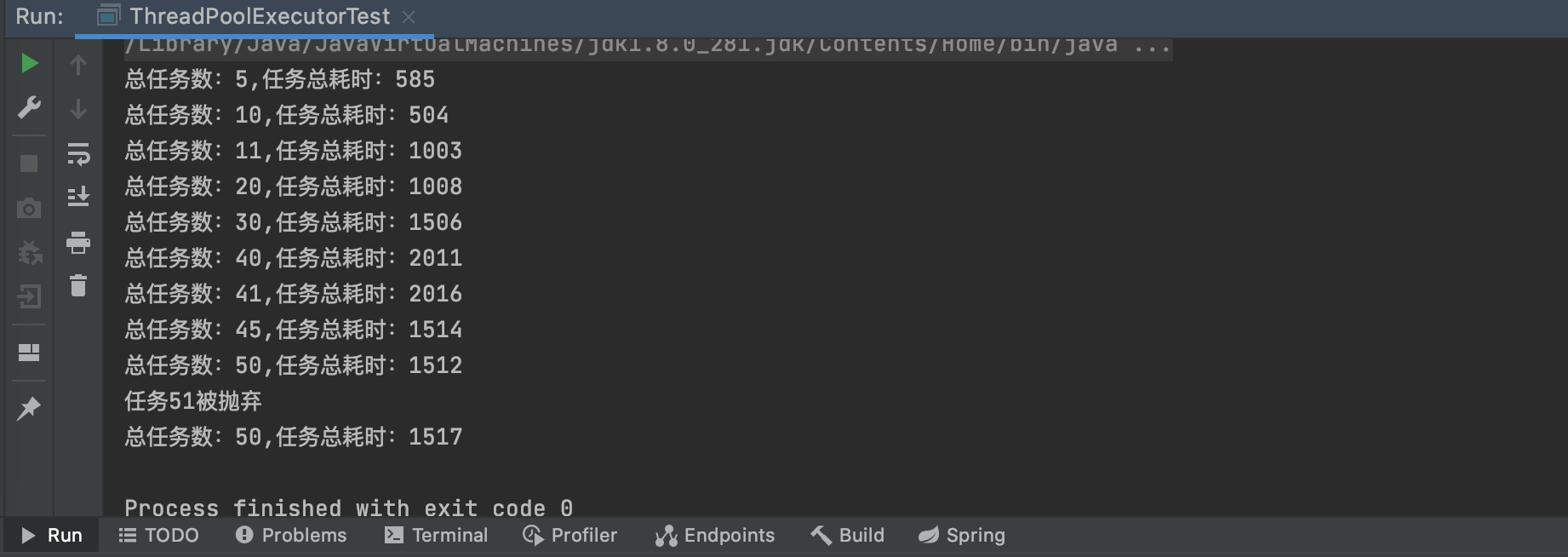
我们画个表格来对比一下,核心线程数是10,每一个执行耗时500ms,因为main线程启动是要时间的,再加上线程是异常执行的,所以多出来85毫秒或一些啰嗦时间这个可以理解为线程预热。
- 5个任务或10个任务大概理论500毫秒左右执行完是能理解的;
- 从11个任务到30个开始就会多出500~1500毫秒来,是因为任务数没有达到满队列,最大线程数据没有被激活,所以30 \ 10 * 500 = 1500ms;
- 当任务数到40个的时候为什么会是两秒呢?这里很多人已经想到了,队列不是30吗?这里40已经满了呀。其实有十个在工作队列已经被取出来执行任务了,所以队列还是能存放30个任务,所以执行玩当前一组10个任务还有30个任务继续分成3组执行,就是4组需要2000ms。
- 重点来了。依照第三步所说,这里余下的是31个线程,这回应该要新建线程到20个了吧,如果是20个线程那么10一组另外31个会变成20一组+11一组就是耗时1500ms,然而现实就非我所愿还是2000ms,这是为什么呢?
- 45个任务的时候确实是用了20个最大线程数,50个也是,51个由于拒绝策略实际就执行50个任务,这里耗时1500ms也无悬念。45任务(10一组+20一组+15个一组)、50任务(10一组+20一组+20个一组)就是三组任务耗时1500ms。
这里有个公式:
| --------- | ------------------------------------------------------------------------------------ | -------------------------------------------- |
|---|---|---|
| 公式① | 任务数 <= 核心线程数 | 线程池中工作线程数 = 任务数 |
| 公式② | 核心线程数 < 任务数 <= 最大线程数 + 队列容量时 | 线程池中工作线程数 = 核心线程数 |
| 公式③ | 核心线程数 + 队列容量 < 任务数 <= 最大线程数 + 队列容量时 | 线程池中工作线程数 = 任务数 - 队列容量 |
下列表格换算上面的公式:
| 核心、最大线程数、队列容量 | 总任务数 | 总耗时(ms) | 公式数据 |
|---|---|---|---|
| 10 、 20 、 30 | 5 | 585 | ① 执行批次为5 =》1 * 500 |
| 10 、 20 、 30 | 10 | 504 | ① 执行批次为10 =》1 * 500 |
| 10 、 20 、 30 | 11 | 1003 | ②执行批次为10 + 1 =》2 * 500 |
| 10 、 20 、 30 | 20 | 1008 | ② 10 + 10 =》2 * 500 |
| 10 、 20 、 30 | 30 | 1506 | ② 10 + 10 + 10 =》3 * 500 |
| 10 、 20 、 30 | 40 | 2011 | ② 执行批次为10 + 10 + 10 + 10 =》4 * 500 |
| 10 、 20 、 30 | 41 | 2016 | ③ 41-30=11,执行批次为11+11+11+8 =》4 * 500 |
| 10 、 20 、 30 | 45 | 1514 | ③ 45-30=15,执行批次为15+15+15 =》3 * 500 |
| 10 、 20 、 30 | 50 | 1512 | ③ 50-30=20,执行批次为20+20+10 =》3 * 500 |
| 10 、 20 、 30 | 51 | 1517 | 拒绝了一个任务等同上 |
最后
遗留一个问题,如果是44个任务,最终的结果是耗时多少秒呢?各位去算一下吧。